
ETL vs ELT
Comprendre les avantages et les inconvénients de chacune des approches

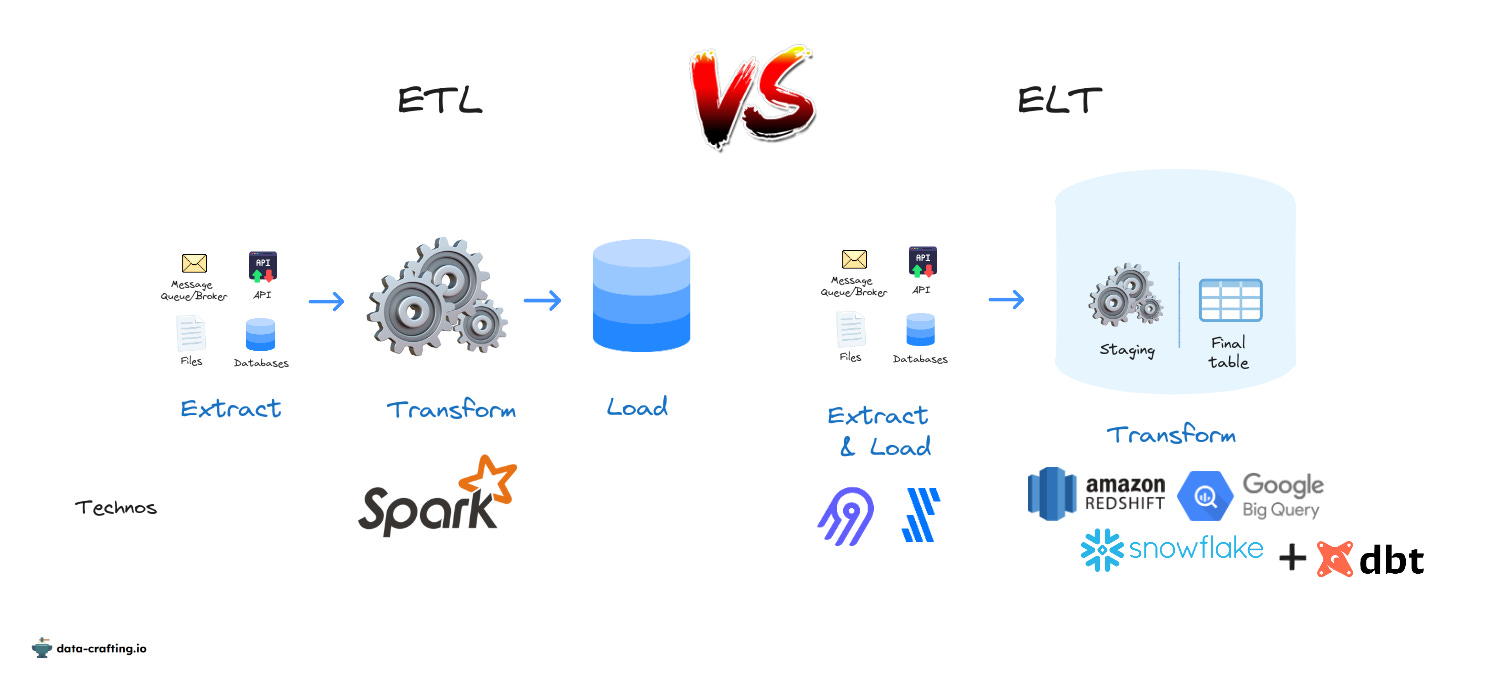
ETL vs ELT
Dans ce nouveau numéro de la newsletter, j’aimerais revenir sur le sujet que j’ai abordé lors de mon intervention au podcast Datawatch : la comparaison entre ETL et ELT.
Depuis l’utilisation des premiers datawarehouses pour la BI (Business Intelligence) dans les années 80/90 jusque dans les années 2010, l’ETL a principalement régné.

Florilège de quelques outils ETL utilisés à l’époque
Au début, les outils ETL n’étaient pas scalables et ne permettaient pas de traiter des données en parallèle. L’essor du Big Data dans les années 2000 (avec l’arrivée de MapReduce puis de Spark en 2009) et l’essor du cloud ont progressivement changé cela.
L’émergence des Datawarehouses dans le cloud séparant le "compute" (moteur de calcul) et le stockage ont également rebattu les cartes. Une nouvelle approche a vu le jour : ELT, pour Extract, Load & Transform.
Parmi ces nouveaux Data Warehouses, on peut citer Redshift, BigQuery et Snowflake.
En effet, le coût du stockage, qui était élevé dans les années 80/90, n’a fait que diminuer depuis. Aujourd’hui, le stockage ne coûte quasiment rien. Donc stocker toutes les données brutes dans un datawarehouse n’est plus un problème.

Différences entre ETL et ELT
L’approche ELT présente de nombreux avantages :
Un gain de flexibilité, car il n’est plus nécessaire de développer entièrement une pipeline ETL pour avoir accès aux données. L’approche ELT permet d’avoir toutes les données brutes et de choisir lesquelles traiter pour ensuite les fournir aux utilisateurs finaux.
Un gain en termes de rapidité de développement, car il n’est plus nécessaire de déplacer les données d’un serveur à l’autre comme pour l’ETL. Les transformations se font à l’aide du SQL.
Ce qui permet à d’autres profils, tels que les analytics engineers, de s’occuper des transformations et d’apporter en plus leurs connaissances métier.
Cette approche est très bien adaptée au monde de la Business Intelligence, qui sert à récupérer les données produites par l’entreprise pour les analyser et fournir des mesures permettant de piloter ensuite l’entreprise.
Des outils comme DBT et l’approche Modern Data Stack ont largement contribué à sa popularisation.
Cependant, l’ELT n’est pas la panacée et nous avons toujours besoin de l’ETL.
L’ETL reste pertinent si nous souhaitons maîtriser nos coûts, notamment dans le Big Data. Stocker plusieurs pétaoctets dans BigQuery pour ensuite les traiter n’est pas l’approche la plus économique. Le compute et le stockage sont séparés, mais le compute reste cher. De plus, si nous n’avons pas besoin de stocker les données brutes d’un traitement à l’autre, alors il n’y a aucun intérêt à adopter une approche ELT.
Pour ce cas précis (très gros volume de données, aucun besoin de garder les données brutes), une approche ELT, que ce soit dans un Datawarehouse ou dans un Data Lake, n’est pas pertinente selon moi.
Dans la vidéo, je donne l’exemple de l’entreprise Meltwater qui récupère des données de plusieurs réseaux sociaux pour les traiter, les enrichir et les stocker d’une semaine à l’autre dans un cluster Elasticsearch. Faire une sauvegarde des données des réseaux sociaux chaque semaine est trop coûteux et n’a pas grand intérêt.
Si nous ne sommes pas en présence de données structurées et relationnelles, mais plutôt de données semi-structurées (données de sites web, réseaux sociaux, données de capteurs) voire non structurées (comme des images), stocker ces données dans un Data Lake peut être plus pertinent, notamment pour faire du Machine Learning.
Si nous ne sommes pas dans le cadre de la BI, mais que nous traitons des données pour alimenter le backend d’une application développée par nos soins, il peut être plus intéressant de ne pas avoir recours à des solutions couteuses et propriétaire comme les Data Warehouses dans le cloud, mais plutôt à des solutions open source pour mieux maîtriser ses coûts et éviter le vendor lock-in.
Une troisième approche que je n’ai pas encore mentionnée est l’approche ETLT. Cette approche essaye de prendre le meilleur des deux mondes en évitant les inconvénients des deux.
Avec l’approche ETLT, nous commençons par une approche ETL pour faire un premier filtre sur les données que nous souhaitons garder, nettoyer et formater en partie les données en enlevant les doublons par exemple. On peut également masquer ou enlever les données sensibles. Même si les Data Warehouses dans le cloud ont maintenant des fonctionnalités d’anonymisation, régler le problème en amont avant de charger les données dans le Data Warehouse reste plus sécurisé.
Pourquoi discuter de tout ça ? L’intérêt pour moi est de se rappeler des grandes idées derrière ces deux approches (trois si on compte l’ETLT) et d’identifier dans quoi nous nous lançons lorsque nous choisissons de mettre en place une approche plutôt qu’une autre.
Je vous mets le lien de mon intervention dans le podcast Datawatch :
J’espère que vous avez apprécié cet article, n’hésitez pas à le partager avec vos ami.e.s !