


[JOUR 19] II. Python, the right way : Ecrire du bon code
Le chemin vers un code de qualité est semé d'embûches.

Sommaire :
I.Introduction
II.Les spécificités du code et la doc
1)PEP
2)Docstring et commentaires
3)Linting et formating
Article précédent :
![[JOUR 18] II. Python, the right way : Types, Type Hints et Mypy](https://substackcdn.com/image/fetch/$s_!DE0l!,w_140,h_140,c_fill,f_webp,q_auto:good,fl_progressive:steep,g_auto/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F81c27778-ae4c-44dc-acb6-545f6c14c11f_616x550.png)
I.Introduction
Après avoir vu comment réduire le nombre d’erreurs dues aux problèmes de types, je souhaiterais vous présenter plus en détail les éléments qui vont différencier le code d’un non-initié de celui d’un professionnel.
Un code professionnel n’est pas nécessairement plus complexe, mais c’est un code qui tire parti de l’expérience accumulée de la communauté des développeurs à travers les années et les décennies.
Ce qui diffère entre un code écrit sur les bancs de l’école et celui écrit dans une entreprise ce sont les enjeux.
En entreprise :
Vous écrivez du code à plusieurs.
Vous coûtez de l’argent à l’entreprise.
Le code que vous produisez a une valeur monétaire.
Le code que vous écrivez est déployé et accessible à des utilisateurs.
Ce code sert à générer du profit pour l’entreprise.
Donc l’idéal pour une entreprise et pour vous est de :
Collaborer le plus efficacement possible entre développeurs.
Passer le moins de temps possible à écrire du code, ou à modifier le code existant.
Limiter, voire réduire à néant, le nombre de problèmes (bugs et sécurité) liés au code.
En prenant l’écriture de code sous cette nouvelle perspective, la communauté des développeurs s’est interrogée, concertée et a appris de ses erreurs.
Les enseignements tirés de ce processus sont généralement appelés les “bonnes pratiques” et sont rattachés à ce qu’on appelle le “software craftsmanship” ou l’artisanat logiciel.
Les bonnes pratiques sont donc un ensemble d’aides qui vous permettent a priori de mieux faire votre travail de développeurs, mais ce ne sont pas des règles absolues à employer tout le temps.
Primo, la règle absolue avant de se prendre la tête sur les bonnes pratiques est que votre code fonctionne ! On vous paye pour délivrer quelque chose de fonctionnel en temps et en heure. Vous n’allez pas manquer une deadline juste pour écrire du joli code, gardez ça en tête. La subtilité est que, sur le moyen/long terme, vous aurez de plus en plus de mal à modifier le code s’il est écrit n’importe comment, c’est ce qu’on appelle la dette technique, gardez ça aussi en tête.
Deuxio, dites-vous bien que les bonnes pratiques sont là pour solutionner un problème et non pour vous tordre le bras. J’écris ces lignes car elles sont parfois décriées car elles peuvent être utilisées par certains pour asseoir une autorité ou dévaloriser d’autres développeurs : “Wouah, tu ne connais pas le TDD, tu dois être un mauvais développeur”.
Le but des bonnes pratiques est de comprendre ce qu’elles solutionnent, quand elles sont utiles et de les partager avec altruisme entre développeurs (c’est-à-dire pour aider l’autre et non le rabaisser). L’idée est que vous ayez une boîte à outils de bonnes pratiques pour vous éviter des problèmes à vous et à votre équipe.
Mais revenons aux “problèmes” que vous pouvez rencontrer et aux solutions pour y pallier :
En tant que développeurs, vous passez plus de temps à lire du code qu’à coder.
Et oui, ça peut paraître contre-intuitif, mais vous passez environ 80% de votre temps de développeur à lire du code. Pour aller plus loin d’ailleurs, vous passez plus de temps non seulement à lire mais aussi à débugger du code qu’à en écrire. Vous ne passez qu’environ quelques pourcents de votre temps à réellement écrire du code…
Pour rappel, un développeur ça coûte de l’argent, c’est d’ailleurs l’un des principaux postes de dépenses d’une entreprise du logiciel, la masse salariale. Donc optimiser la lecture du code est primordial pour économiser de l’argent.
Le code est modifié sans cesse. Vous devez pouvoir le modifier simplement et sans accroc.
La base de code est vouée à grossir et à devenir de plus en plus complexe. Gérer cette complexité est un défi de tous les jours.
En conclusion, il nous faut un code lisible, maintenable, testable et extensible (que l'on peut faire évoluer simplement).
Un moyen simple d’estimer la qualité de votre code est le nombre de WTF par minute lorsque vos collègues essayent de comprendre votre code ;) ("What the fuck" est une expression anglaise familière utilisée pour exprimer son étonnement, on peut la remplacer par des jurons usuels en français) :

Mais comment arrive-t-on à produire un code de qualité possédant ces quatre caractéristiques principales ? Eh bien, si vous appliquez les dix principes suivants, vous aurez fait une très grosse partie du chemin :

Sur le schéma ci-dessous, vous voyez différents concepts. Dans le reste de la formation, nous nous attarderons plus ou moins sur certains de ces concepts.
Deux remarques avant toute chose : certains de ces concepts font écho à d’autres, ainsi des idées que nous trouverons à certains moments se retrouveront à d'autres endroits, appliquées différemment. Au-delà de vous faire un listing de tous les bons principes, ma volonté est de vous permettre de construire une “culture” à propos l’ingénierie logicielle qui vous servira dans n’importe quel job de développeur.
Je vous l’ai dit plus haut, mais optimiser la lecture du code est primordiale. Comment optimise-t-on cela ? En écrivant du code clair, simple, facilement compréhensible.
C’est l’idée principale derrière les principes 1 à 3. Et c’est ce que nous allons voir plus en détails maintenant.
II. Les spécificités du code et la doc
Il existe généralement des conventions de nommage pour les langages, c’est-à-dire une manière standardisée de nommer et organiser les éléments du code. Sous Python, ces conventions sont explicitées par les PEP.
1) PEP
PEP signifie Python Enhancement Proposal (Proposition d'Amélioration de Python). C'est un document de conception qui joue un rôle crucial dans l'évolution et l'amélioration du langage Python.
Les PEP servent plusieurs objectifs importants :
Fournir des informations à la communauté Python.
Décrire de nouvelles fonctionnalités pour Python.
Documenter les processus ou l'environnement Python.
Proposer des modifications au langage ou à ses bibliothèques standard.
Établir des normes et des bonnes pratiques.
La PEP 8 est l'une des plus connues. Elle établit des conventions de style pour le code Python, visant à améliorer la lisibilité et la cohérence du code.
Par exemple, elle recommande :
L'utilisation de 4 espaces pour l'indentation.
Une limite de 79 caractères par ligne.
Des conventions de nommage spécifiques (le snake case, à la place du camel case ou du kebab case).
En suivant ces directives, les développeurs peuvent créer un code plus uniforme et plus facile à lire pour l'ensemble de la communauté Python.

2) Docstring et commentaires
Python fournit un moyen de documenter élégamment son code grâce à la docstring. La docstring est généralement utilisée pour expliciter le fonctionnement des fonctions et des classes.
L’avantage de la docstring est qu’elle apparaîtra ensuite lorsque vous emploierez votre fonction/classe à un autre endroit du code. Vous pourrez ainsi, en survolant le code avec votre souris, voir s’afficher la docstring.
Un autre avantage est qu’il existe des outils permettant de générer une documentation sous format HTML à partir de la docstring que vous avez écrite. Grâce à cela, vous pouvez avoir un site statique avec toutes les informations sur les éléments de votre code, ce qui peut être utile aux autres développeurs de l’entreprise.
En termes de convention, une manière populaire d’écrire la docstring est celle employée par Google.
Elle se présente ainsi pour les fonctions :
def fetch_smalltable_rows(
table_handle: smalltable.Table,
keys: Sequence[bytes | str],
require_all_keys: bool = False,
) -> Mapping[bytes, tuple[str, ...]]:
"""Récupère les lignes d'une Smalltable.
Extrait les lignes correspondant aux clés données de l'instance de Table
représentée par table_handle. Les clés de type string seront encodées en UTF-8.
Args:
table_handle: Une instance de smalltable.Table ouverte.
keys: Une séquence de strings représentant la clé de chaque ligne de table
à récupérer. Les clés de type string seront encodées en UTF-8.
require_all_keys: Si True, seules les lignes avec des valeurs définies pour toutes les clés seront
renvoyées.
Returns:
Un dictionnaire associant les clés aux données de ligne de table correspondantes
récupérées. Chaque ligne est représentée par un tuple de strings. Par exemple :
{b'Serak': ('Rigel VII', 'Preparer'),
b'Zim': ('Irk', 'Invader'),
b'Lrrr': ('Omicron Persei 8', 'Emperor')}
Les clés retournées sont toujours en bytes. Si une clé de l'argument keys est
absente du dictionnaire, alors cette ligne n'a pas été trouvée dans la
table (et require_all_keys devait être False).
Raises:
IOError: Une erreur s'est produite lors de l'accès à la smalltable.
"""
Vous remarquerez quatre sections : une phrase expliquant le fonctionnement général de la fonction, une partie dédiée aux arguments, une partie pour les valeurs retournées, et une partie pour les erreurs levées. Chaque section peut comporter des explications et exemples supplémentaires. La partie "Raises" sert à expliciter les erreurs ou exceptions pouvant être retournées par le code. Nous verrons plus en détails les erreurs et exceptions dans une autre partie du cours.
Concernant les commentaires, ils s'écrivent préfixés d'un #. Voici quelques règles concernant les commentaires :
Essayez d'écrire du code compréhensible qui ne nécessite pas de commentaire (nous verrons dans le second article comment écrire du code compréhensible). Si cela s'avère impossible, prenez le temps d'écrire un bon commentaire concis.
Ne soyez pas redondant (par exemple :
if a==b; # si a égale à b).Ne laissez pas de code commenté ; supprimez-le plutôt.
Utilisez des commentaires pour expliquer l'intention derrière le code.
Employez également des commentaires pour avertir des conséquences potentielles.
En plus de tout cela, pour les codes parfois complexes, comme les algorithmes, des documents textuels ainsi que des schémas peuvent être fournis pour aider encore plus à la compréhension de ceux-ci.
3) Linting et formating
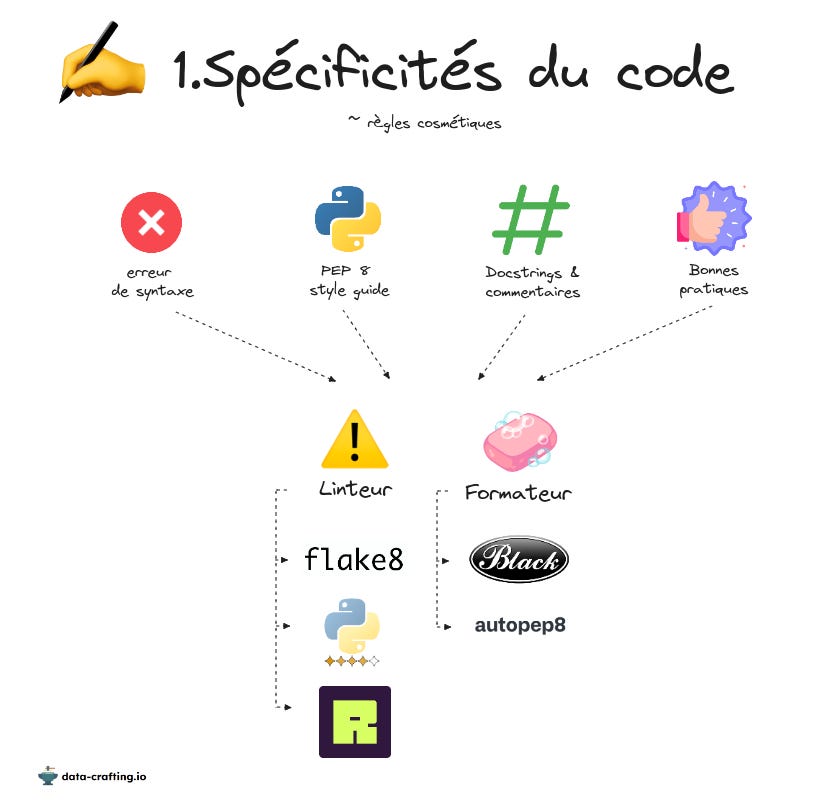
Pour renforcer les règles vues précédemment, il existe deux types d’outils :
Les linters : qui vous soulignent les problèmes remarqués dans votre code, s’il ne respecte pas les règles définies/établies.
Les formateurs : qui modifient et mettent en forme votre code d’après les règles que vous avez définies.
Je veux vous présenter un linter et un formateur populaires.
Ruff : Ruff est un linter classique, hormis qu’il est écrit en Rust, il fait donc tout ce que font les autres linter mais 10 fois plus rapidement.
Black : Le formateur dogmatique. Black vous formate votre code sans vous demander votre avis et c’est un vrai plaisir. Plus besoin de se prendre la tête, le même formatage est appliqué chez tout le monde. Je vous recommande Black pour vos projets.
Pour utiliser Black, suivez ces étapes :
Installez Black dans un projet uv :
uv add black
Utilisation de base
Pour formater un fichier ou un répertoire :
black {fichier_source_ou_répertoire}
Options courantes
-check: Vérifie si les fichiers seraient reformatés sans les modifier.-diff: Affiche les différences sans reformater les fichiers.-line-length: Définit la longueur maximale des lignes (par défaut 88).
Intégration
Black peut être intégré dans des éditeurs comme Visual Studio Code.
Il peut être utilisé dans des processus CI/CD pour maintenir un style cohérent.
Configuration
Modifiez le fichier pyproject.toml pour configurer Black. Par exemple :
[tool.black]
line-length = 88
target-version = ['py38']
Pour plus de détails, je vous invite à lire la documentation de Black.
Avec cela, nous venons de couvrir les principes 1 et 2 des dix principes pour écrire du code de haute qualité. Nous continuerons la liste dans les prochains numéros.