
[JOUR 21] II. Python, the right way : Les principes SOLID
Faites du code orientée objet structuré, maintenable et évolutif.

Sommaire :
I. Rappels : interface en Python
II. Les principes SOLID
1.Principe de responsabilité unique
2.Principe ouvert/fermé
3.Principe de substitution de Liskov
4.Principe de ségrégation des interfaces
5.Inversion de dépendance
Article précédent :
![[JOUR 20] II. Python, the right way : Les préceptes du Clean Code](https://substackcdn.com/image/fetch/$s_!J5iZ!,w_140,h_140,c_fill,f_webp,q_auto:good,fl_progressive:steep,g_auto/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fb4c348aa-c8da-487e-8305-df2d5c019424_310x301.png)
I. Rappels : interface en Python
Les principes SOLID sont intimement liés à la programmation orientée objet. Avant d'aller plus loin, vous devez connaître les principes d’héritage, d’encapsulation, de polymorphisme et d’abstraction.
Un concept clé en POO est celui d’interface. Une interface agit comme un contrat où l’on définit les attributs (valeurs) et méthodes (fonctions) que nous aimerions avoir dans notre classe. Les classes peuvent hériter des interfaces. Ce qui est génial, c’est que nous pouvons dans notre code faire référence à des interfaces, les manipuler, etc., sans se préoccuper de la vraie classe utilisée en arrière-plan. Cette idée permet de réaliser beaucoup de choses.
Les principes SOLID tirent pleinement parti de ces mécanismes pour offrir un code lisible, maintenable, testable et extensible. Nous explorerons cela dans la suite de cet article.
Pour rappel, Python n’a pas réellement d'interfaces comme dans d'autres langages tels que Java.
Pour créer une interface en Python, il vous suffit de créer une classe parente et de la faire hériter à une sous-classe.
Par exemple :
class AnimalInterface:
def __init__(self, name):
self.name = name
def move(self) -> None:
print(f"the animal {self.name} moves")
class Fish(AnimalInterface):
def move(self) -> None:
print(f"the fish {self.name} swims")
if __name__ == "__main__":
nemo = Fish("nemo")
nemo.move() # Résultat: the fish nemo swims
Nous pouvons aussi créer une classe abstraite pour répondre au même besoin.
Une classe abstraite est une classe dont au moins une méthode est abstraite.
Qu’est-ce qu’une méthode abstraite ? Une méthode abstraite est une méthode avec seulement un en-tête. Elle oblige toute classe qui hérite de la classe abstraite à implémenter cette méthode abstraite.
C’est un moyen de s’assurer que chaque classe aura sa propre méthode définie.
Exemple :
from abc import ABC, abstractmethod
class Vehicule(ABC):
@abstractmethod
def afficher_vitesse(self) -> None:
pass
class Voiture(Vehicule):
def __init__(self, vitesse:int):
self.vitesse = vitesse
def afficher_vitesse(self) -> None:
# Obligation d'implémenter cette méthode
print(f"La vitesse de la voiture est {self.vitesse} km/h")
# Utilisation
voiture = Voiture(120)
voiture.afficher_vitesse()
II. Les principes SOLID
Dans la suite de cet article, je partagerai des détails d’implémentation pour chaque principe SOLID. Gardez à l’esprit que ce qui est important, ce sont les idées derrière les principes plutôt que les détails d’implémentation. Si vous ne vous rappelez pas exactement comment implémenter un principe, ce n’est pas très grave.
L'essentiel est :
De garder ces principes en tête lorsque vous développez du code, afin d’itérer dans la meilleure direction possible.
Pour tous les principes que nous explorons, ce n’est pas grave si nous ne les appliquons pas correctement dès la première conception. L'idée est de concevoir un logiciel qui peut être facilement étendu et modifié, et qui peut évoluer vers une version plus stable.
D’identifier les parties de code qui enfreignent ces principes afin de les améliorer par la suite.
Les idées derrière SOLID sont puissantes et vous seront utiles dès que vous aurez à écrire du code un peu plus élaboré en orienté objet. Ces principes, encore une fois, comme les bonnes pratiques, sont là avant tout pour vous simplifier la vie. De surcroît, je vous garantie qu’ils vous apporteront de la satisfaction lorsque vous les appliquerez. ;)
Voici la liste de ces principes :
S comme SRP pour Single Responsibility Principle
O comme OCP pour Open Closed Principle
L pour Liskov’s Substitution Principle
I pour Interface Segregation Principle
D comme Dependency Inversion Principle
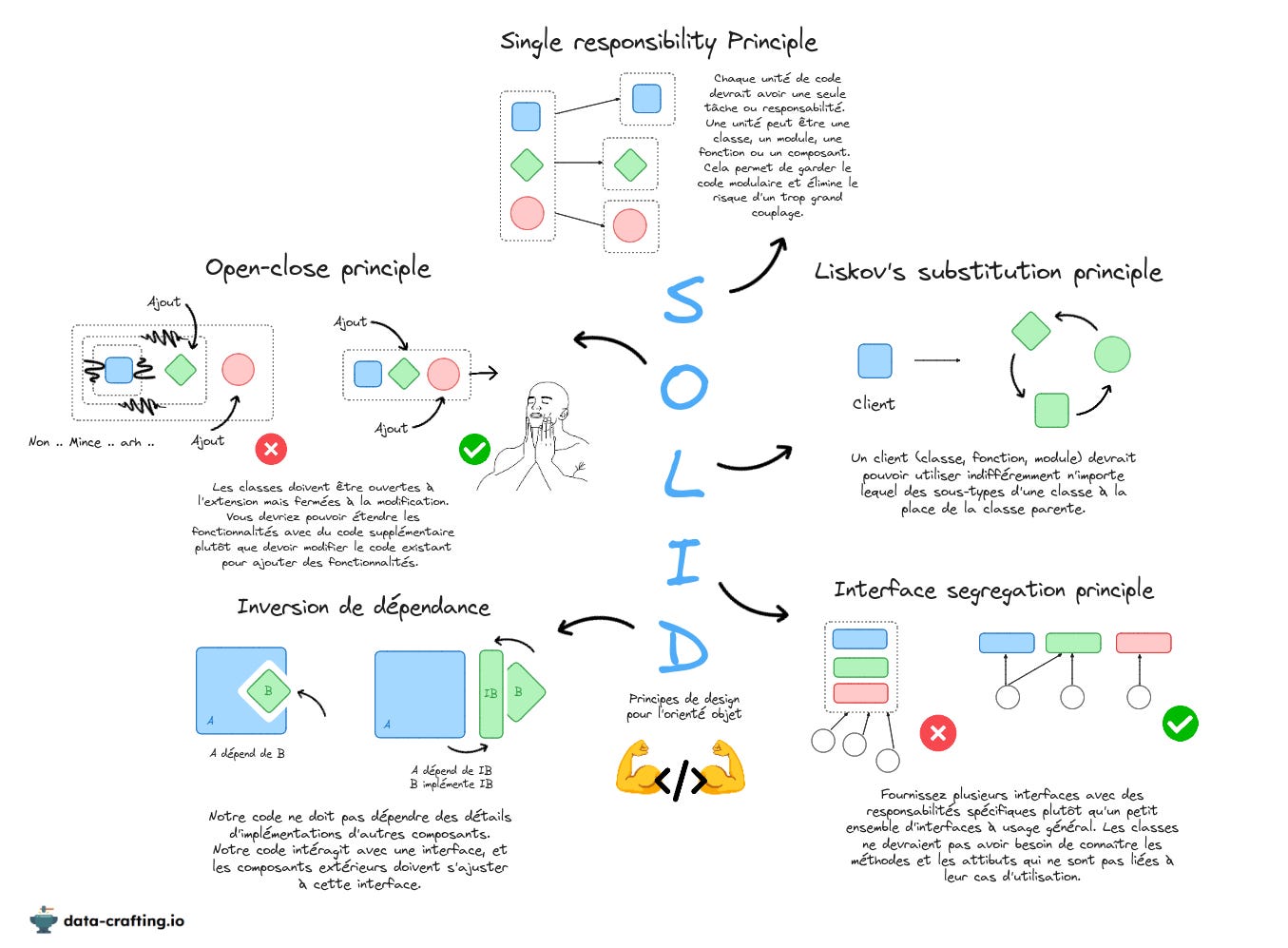
I. Principe de responsabilité unique
Si vous êtes familier avec ce concept grâce à mes articles précédents, vous savez que le principe de responsabilité unique stipule qu’une classe doit faire une seule chose et la faire bien. Cela signifie que la classe n’a qu’une seule raison de changer. Seulement si un aspect du problème métier change, alors la classe pourrait nécessiter une modification.
À l’inverse, les objets qui font tout et qui possèdent trop d’attributs représentent un antipattern.
Plus une classe est petite, mieux c’est.
Une clarification importante est que ce principe ne signifie pas que chaque classe doit avoir une seule méthode. Les classes peuvent avoir plusieurs méthodes, tant qu'elles s’alignent sur la même logique que celle que la classe est censée gérer.
Nous allons voir un exemple, sans avoir besoin de développer en détail l’implémentation des classes et des méthodes pour illustrer ce principe.
# Exemple sans application du principe SRP
class CustomerService:
def send_email_to_customer(): ...
def calculate_customer_bill(): ...
def get_customer_infos(): ...
#===============================================#
# Application du principe SRP
class CustomerEmail:
# Responsable de la gestion des e-mails des clients
def send_email_to_customer(customer: Customer, email_content: str): ...
class CustomerBillCalculator:
# Responsable du calcul des factures des clients
# Voici à quoi pourrait ressembler l'en-tête de la fonction #calculate_customer_bill.
def calculate_customer_bill(customer: Customer, purchases: list[Items], countryTax: CountryTax): ...
class Customer:
# Responsable de l'entité client
def get_customer_infos(): ...
class CustomerService:
# Exemple de méthode utilisant nos autres classes
def send_email_with_bill_to_customer(customer_email: CustomerEmail, customer_bill: CustomerBillCalculator, customer: Customer):
# Si la méthode de calcul de la facture change, cette classe
# n'a pas besoin de le savoir.
bill = customer_bill.calculate_customer_bill(customer, ...)
#Si la méthode d'envoi des e-mails change, idem.
customer_email.send_email_to_customer(customer, bill)
Nous constatons tout d'abord que la classe CustomerService originale englobe de nombreuses fonctions. Même si toutes ces méthodes concernent le client, cela ne justifie pas de les regrouper dans la même classe. Par exemple, l'envoi d'un e-mail implique de construire le contenu du mail, de définir l’en-tête, et d'utiliser du code spécifique pour gérer l'envoi. Pourquoi ces responsabilités devraient-elles impacter la classe CustomerService si la méthode d’envoi des e-mails change ?
Dans la seconde partie de l'exemple, je montre que si la logique d'envoi des e-mails doit changer, cela peut se faire simplement dans la classe CustomerEmail, sans affecter les autres classes.
De même pour la logique de calcul de la facture avec CustomerBillCalculator.
Nous avons ainsi mieux séparé les responsabilités, ce qui permet de faire évoluer les différentes parties du code indépendamment.
En règle générale, si vous concevez un composant (disons une classe) et qu'il y a beaucoup de choses différentes à faire, dès le début, vous pouvez anticiper que cela ne se terminera pas bien, et que vous devez séparer les responsabilités.
C'est un bon début, mais la question suivante est : quelles sont les bonnes limites pour séparer les responsabilités ? Pour comprendre cela, vous pouvez commencer par écrire une classe monolithique, afin de comprendre quelles sont les collaborations internes et comment les responsabilités sont distribuées. Cela vous aidera à obtenir une image plus claire des nouvelles abstractions qui doivent être créées.
Le Principe de Responsabilité Unique (SRP) est lié à la notion de cohésion en conception logicielle, qui vise à ce que les classes utilisent la majorité de leurs propriétés et attributs dans leurs méthodes, assurant ainsi un regroupement logique sous une même abstraction. Si une classe présente des méthodes qui ne sont pas interconnectées, elles révèlent des responsabilités distinctes et devraient être scindées en classes plus petites pour améliorer la cohésion.
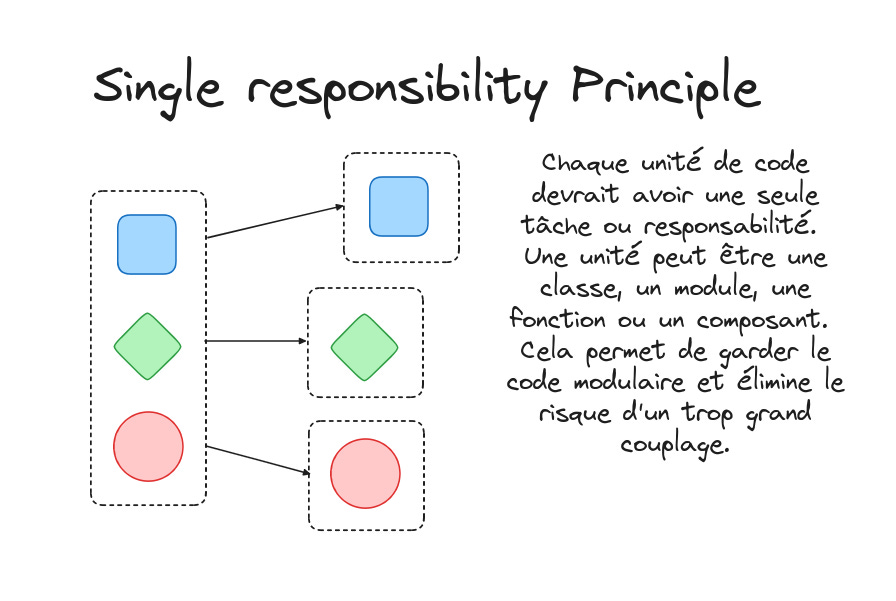
2. Principe ouvert/fermé (OCP)
Le principe Ouvert/Fermé (OCP) stipule qu'une classe doit être à la fois ouverte à l'extension et fermée à la modification, ce qui peut paraître contre-intuitif mais je vais vous détailler ça.
Lors de la conception d'une classe, il est essentiel d'encapsuler soigneusement les détails d'implémentation pour faciliter sa maintenance. En même temps, nous voulons qu'elle soit extensible pour ajouter des fonctionnalités si nécessaire, tout en restant fermée à la modification afin de ne pas devoir changer le code existant à chaque nouvelle fonctionnalité.
Prenons un exemple pour clarifier ce concept :
Imaginons un système où nous recevons des données clients avec des informations telles que le nombre de produits achetés, le montant total dépensé, etc. Nous souhaitons classer ces clients selon plusieurs paramètres pour leur envoyer des promotions adaptées.
Regardez le code ci-dessous. À première vue, le système semble extensible : nous pouvons ajouter une nouvelle sous-classe à Customer et faire en sorte que CustomerClassifier puisse la gérer. Cependant, cela dépend de la méthode utilisée dans CustomerClassifier.
from dataclasses import dataclass
@dataclass #Permet de créer des classes sans __init__
class Customer:
raw_data: dict[str, int]
class SmallCustomer(Customer):
"""A customer who has spent tiny amounts."""
class MediumCustomer(Customer):
"""A customer who has spent some money."""
class BigCustomer(Customer):
"""A customer who has spent lots of money."""
class CustomerClassifier:
def __init__(self, customer_data: dict[str, int]):
self.customer_data = customer_data
def identify_customer(self) -> Customer:
if (self.customer_data["total_amount_spent"] >= 1000 and self.customer_data["nb_items_bought"] >= 100):
return BigCustomer(self.customer_data)
elif (self.customer_data["total_amount_spent"] < 100 and self.customer_data["nb_items_bought"] < 10):
return SmallCustomer(self.customer_data)
else:
return MediumCustomer(self.customer_data)
if __name__ == "__main__":
customer_1 = CustomerClassifier({"total_amount_spent": 200, "nb_items_bought": 15})
print(customer_1.identify_customer())
customer_2 = CustomerClassifier({"total_amount_spent": 1500, "nb_items_bought": 100})
print(customer_2.identify_customer())
customer_3 = CustomerClassifier({"total_amount_spent": 20, "nb_items_bought": 1})
print(customer_3.identify_customer())
Le problème ici est que la logique de classification est centralisée dans une seule méthode. Plus nous ajoutons de types de clients, plus cette méthode s'agrandit. Avoir une méthode qui s'étale sur plusieurs dizaines de lignes remplies de conditions n'est pas souhaitable car elle est difficilement maintenable et lisible.
Pour adhérer à l'open closed principle, nous pouvons modifier la classe Customer qui nous sert d'interface :
class Customer:
def __init__(self, raw_data: dict[str, int]):
self.raw_data = raw_data
@staticmethod
def check_customer_type(customer_data: dict[str, int]) -> bool:
return False
class SmallCustomer(Customer):
@staticmethod
def check_customer_type(customer_data: dict[str, int]) -> bool:
return (customer_data["total_amount_spent"] <= 100 and customer_data["nb_items_bought"] <= 10)
class MediumCustomer(Customer):
@staticmethod
def check_customer_type(customer_data: dict[str, int]) -> bool:
return (100 < customer_data["total_amount_spent"] < 1000 and 10 < customer_data["nb_items_bought"] < 100)
class BigCustomer(Customer):
@staticmethod
def check_customer_type(customer_data: dict[str, int]) -> bool:
return (customer_data["total_amount_spent"] >= 1000 and customer_data["nb_items_bought"] >= 100)
class CustomerClassifier:
def __init__(self, customer_data: dict[str, int]):
self.customer_data = customer_data
def identify_customer(self) -> Customer|None:
for customer_type in Customer.__subclasses__():
try:
if customer_type.check_customer_type(self.customer_data):
return customer_type(self.customer_data)
except KeyError:
continue
return None
if __name__ == "__main__":
customer_1 = CustomerClassifier({"total_amount_spent": 200, "nb_items_bought": 15})
print(customer_1.identify_customer().__class__.__name__)
customer_2 = CustomerClassifier({"total_amount_spent": 1500, "nb_items_bought": 100})
print(customer_2.identify_customer().__class__.__name__)
customer_3 = CustomerClassifier({"total_amount_spent": 20, "nb_items_bought": 1})
print(customer_3.identify_customer().__class__.__name__)
Pour rappel une méthode statique en python est une méthode ne nécessitant pas l’instanciation d’un objet pour être appelée.
La méthode identify_customer n’est plus dépendante des types spécifiques via des conditions, elle se base sur des classes qui ont la même interface. Ces classes ont toutes la même méthode polymorphique check_customer_type.
Merci à la méthode subclasses qui nous permet de retourner la liste des sous classes de Customer. Cette méthode est bien pratique pour notre cas. Pour étendre le nombre de clients pris en charge il suffit de créer une nouvelle classe qui hérite de Customer et d’implémenter la méthode check_customer_type.
Cette nouvelle implémentation assure que la méthode identify_customer n'a pas besoin d'être modifiée pour accueillir un nouveau type de client, tout en permettant l'extension à de nouveaux types de clients par la création de nouvelles classes héritant de Customer et l'implémentation de la méthode check_customer_type.
Pour ajouter un type de client inactif à notre système, nous devons simplement créer la classe suivante :
class InactiveCustomer(Customer):
"""A customer who has not made a purchase."""
@staticmethod
def check_customer_type(customer_data: dict[str, int]) -> bool:
return (customer_data["activate_account"] == False)
Et le tour est joué !
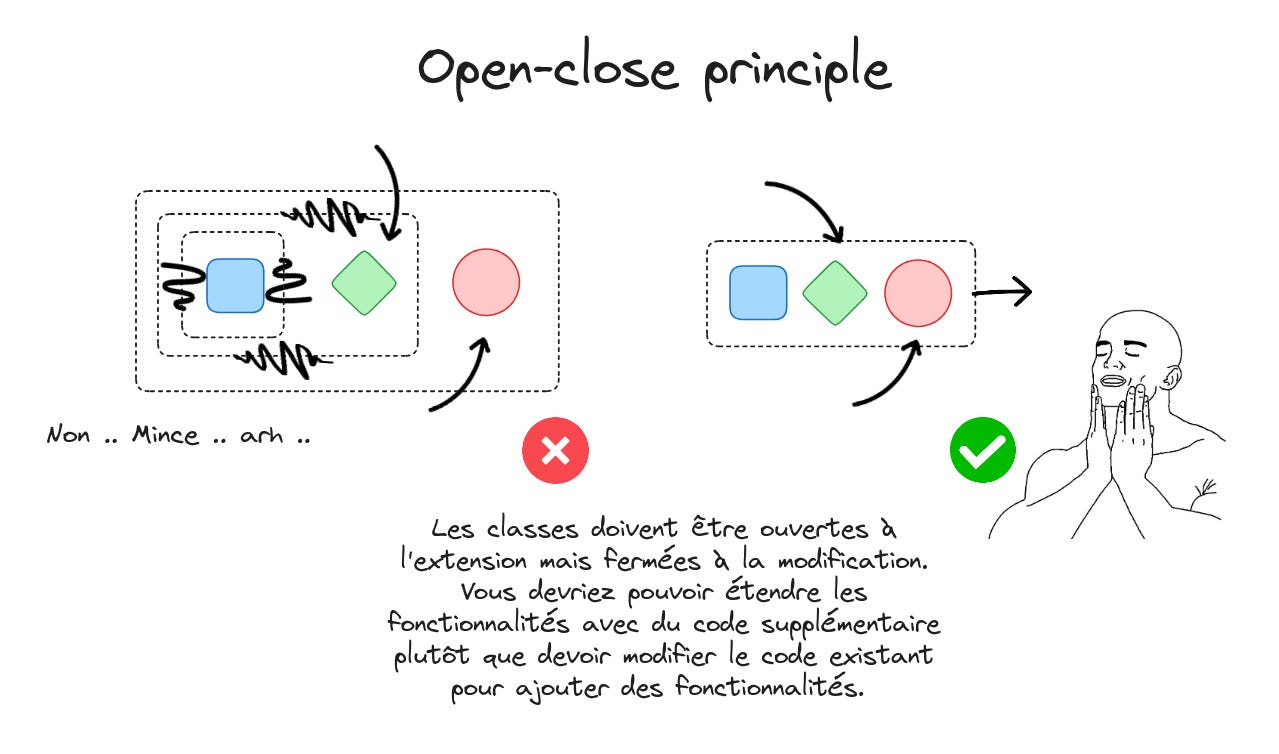
3. Principe de substitution de Liskov (LSP)
La définition de ce principe est la suivante :
Si S est un sous-type de T, alors des objets de type T peuvent être remplacés par des objets de type S, sans que cela ne casse le programme.
Une bonne classe doit définir une interface claire et concise, et tant que les sous-classes respectent cette interface, le programme restera correct. Ce principe est lié à l’idée de concevoir nos interfaces comme des contrats. Il y a un contrat entre un type donné et un client. En suivant les règles du LSP, la conception garantira que les sous-classes respectent les contrats tels qu'ils sont définis par les classes parentes.
Vous pouvez détecter facilement avec l'outil Mypy si cette règle n’est pas respectée.
Par exemple, si nous surchargeons la méthode check_customer_type avec un type d’entrée différent, Mypy nous signalera que nous violons le principe de substitution de Liskov :

4. Ségrégation des interfaces
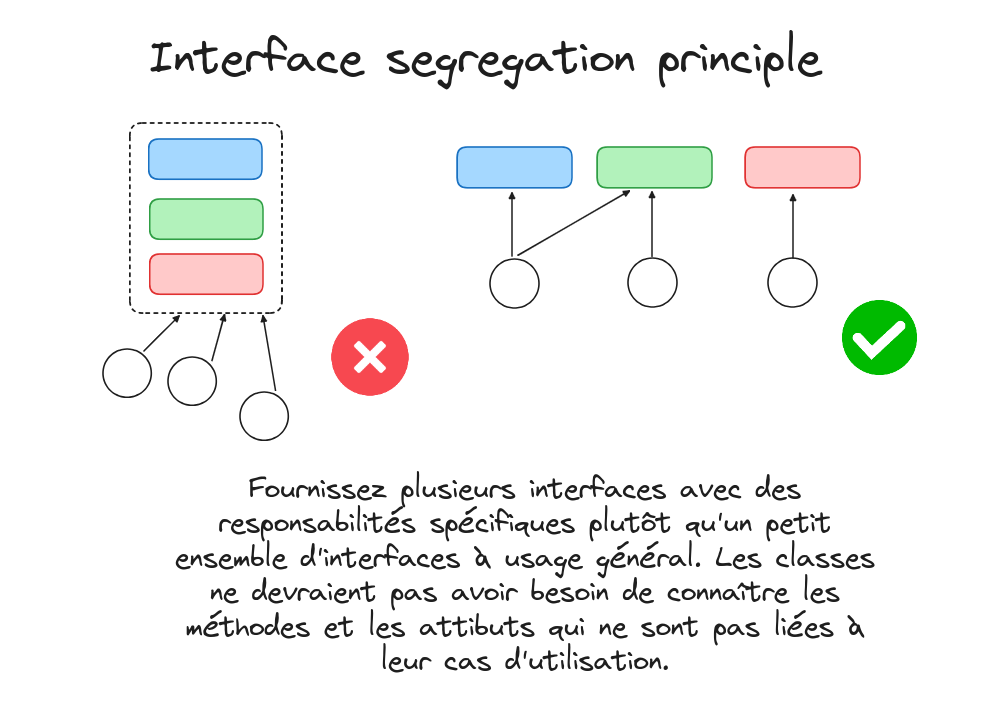
Le principe de ségrégation des Interfaces (ISP) peut se résumer par : "Plus petite est l’interface, mieux c’est."
Ce principe stipule qu'il est préférable de diviser une interface offrant plusieurs méthodes en plusieurs interfaces, chacune contenant moins de méthodes (idéalement une seule), avec un champ d'application très spécifique et précis. Cela permet de favoriser la réutilisabilité du code et d'assurer que chaque classe implémentant ces interfaces soit hautement cohésive (c’est-à-dire des fonctions étroitement liés et des responsabilités claires), possédant un comportement et un ensemble de responsabilités bien définis.
Considérons l'exemple d'une classe abstraite XML_JSON_EventParser :
from abc import ABC, abstractmethod
class XML_JSON_EventParser(ABC):
@abstractmethod
def from_xml(self, xml_data: str) -> None:
"""Parse an event from a source in XML representation."""
@abstractmethod
def from_json(self, json_data: str) -> None:
"""Parse an event from a source in JSON format."""
class CustomerParser(XML_JSON_EventParser):
def from_xml(self, xml_data: str) -> None:
pass
def from_json(self, json_data: str) -> None:
pass
Ici, CustomerParser doit implémenter from_xml même si les données clients sont uniquement en JSON.
Appliquons maintenant la ségrégation d’interfaces :
from abc import ABC, abstractmethod
class XMLEventParser(ABC):
@abstractmethod
def from_xml(self, xml_data: str) -> None:
"""Parse an event from a source in XML representation."""
class JSONEventParser(ABC):
@abstractmethod
def from_json(self, json_data: str) -> None:
"""Parse an event from a source in JSON format."""
class CustomerParser(JSONEventParser):
def from_json(self, json_data: str) -> None:
pass
class EventParser(XMLEventParser, JSONEventParser):
def from_xml(self, xml_data: str) -> None:
pass
def from_json(self, json_data: str) -> None:
pass
Cette approche rend le code plus simple et modulaire.
5. Inversion de dépendance
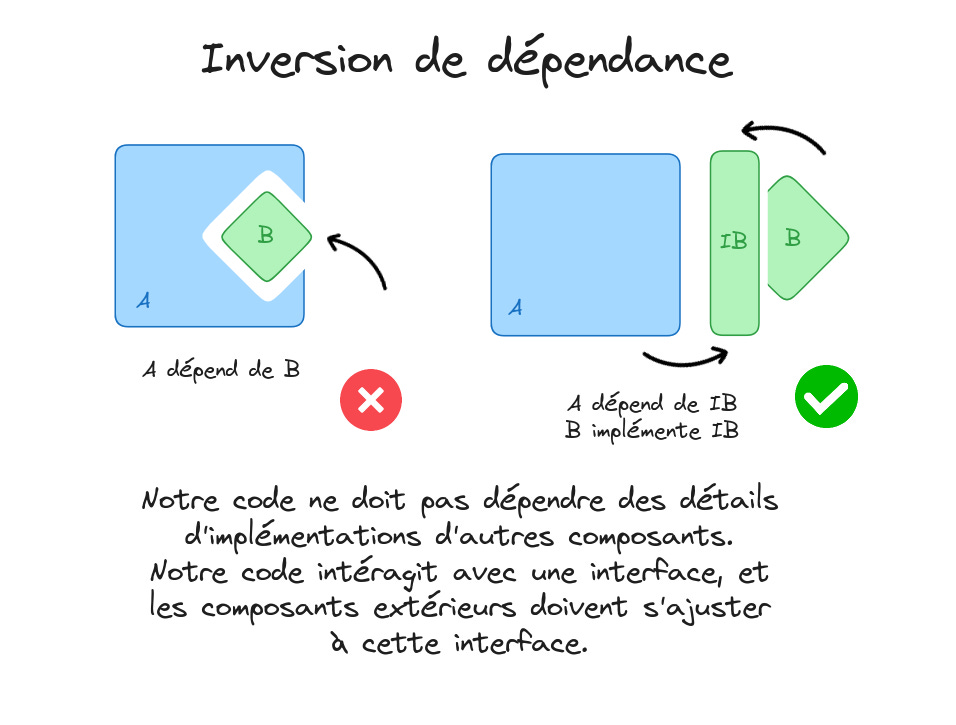
L’inversion de dépendance est un concept puissant utilisé dans beaucoup d’applications. Nous reverrons ce concept au moment de faire des web apis avec fastAPI.
Elle stipule que notre code ne doit pas dépendre des détails d'implémentation d'autres composants. Au lieu de cela, notre code interagit avec une interface, et il incombe aux composants extérieurs de s'adapter à cette interface.
Par exemple, considérons une classe destinée à persister des données à travers une base de données :
from dataclasses import dataclass
from abc import ABC, abstractmethod
@dataclass
class Customer:
id: int
name: str
class Database(ABC):
@abstractmethod
def get_customer(self, customer_id: int) -> Customer|None:
pass
@abstractmethod
def add_customer(self, customer: Customer) -> Customer:
pass
class HandleWebSiteRequest:
def __init__(self, db: Database):
self.db = db
def send_customers_data(self, customer_ids: list[int]) -> list[Customer|None]:
return [self.db.get_customer(id) for id in customer_ids]
Ma classe HandleWebSiteRequest n’est pas dépendante du détail d’implémentation choisi pour la base de donnée. Ce qui veut dire que si je veux changer de type de base de données je n’aurais pas à changer le code de cette classe !
Exemple, créons une classe CSVDatabase :
class CSVDatabase(Database):
def get_customer(self, customer_id:int) -> Customer|None:
#Open a csv file and read it content looking for customer_id
return None
def add_customer(self, customer:Customer) -> Customer:
#add customer data at the end of csv file
return customer
Je peux ensuite faire ce qu’on appelle de l’injection de dépendance :
if __name__ == "__main__" :
csv_db = CSVDatabase()
handler = HandleWebSiteRequest(csv_db) #injection d'une dépendance de type CSVDatabase
Maintenant imaginons que nous préférions stocker nos données dans une base de données relationnelles comme PostgreSQL à la place d’un fichier CSV.
Je créé ma nouvelle classe :
class PostgresDatabase(Database):
def get_customer(self, customer_id:int) -> Customer|None:
#Open a db connection and look for client id in table client
return None
def add_customer(self, customer:Customer) -> Customer:
#do an insert in the table client
return customer
Et ensuite je n’ai qu’à changer l’injection de dépendance :
if __name__ == "__main__" :
#csv_db = CSVDatabase()
pg_db = PostgresDatabase()
handler = HandleWebSiteRequest(pg_db) #injection d'une dépendance de type PostgreDatabase
Et ainsi encore une fois à aucun moment je n’ai eu à modifier le code de la classe HandleWebSiteRequest ;) !
L’inversion de dépendance conclut notre article sur les principes SOLID.
Je vous remercie pour votre lecture.