
Le Change Data Capture pour le Data Engineering
Suivez les changements dans vos bases de données à la transaction près

La matière première du Data Engineer est la base de données relationnelle. C’est l’outil qui est le plus souvent utilisé pour stocker les données des applications de l’entreprise. Le principal travail du Data Engineer est de récupérer toutes les données éparpillées dans les différentes bases de données applicatives et de les rapatrier dans un système de stockage centralisé comme un DataWarehouse historiquement, un Data Lake ou un DataLakehouse plus récemment.
Pour récupérer la donnée, une architecture logique est de créer un réplica (un réplica est une copie exacte de la base de données) de la base de données (pour ne pas trop solliciter la base de données qui reçoit déjà les transactions de l’application) et de requêter ce réplica à intervalle de temps régulier. Le but étant de récupérer toute la nouvelle donnée de ces bases, ou la partie qui nous intéresse, pour alimenter régulièrement notre Data Warehouse. Utilisation classique d’un job ETL programmé.
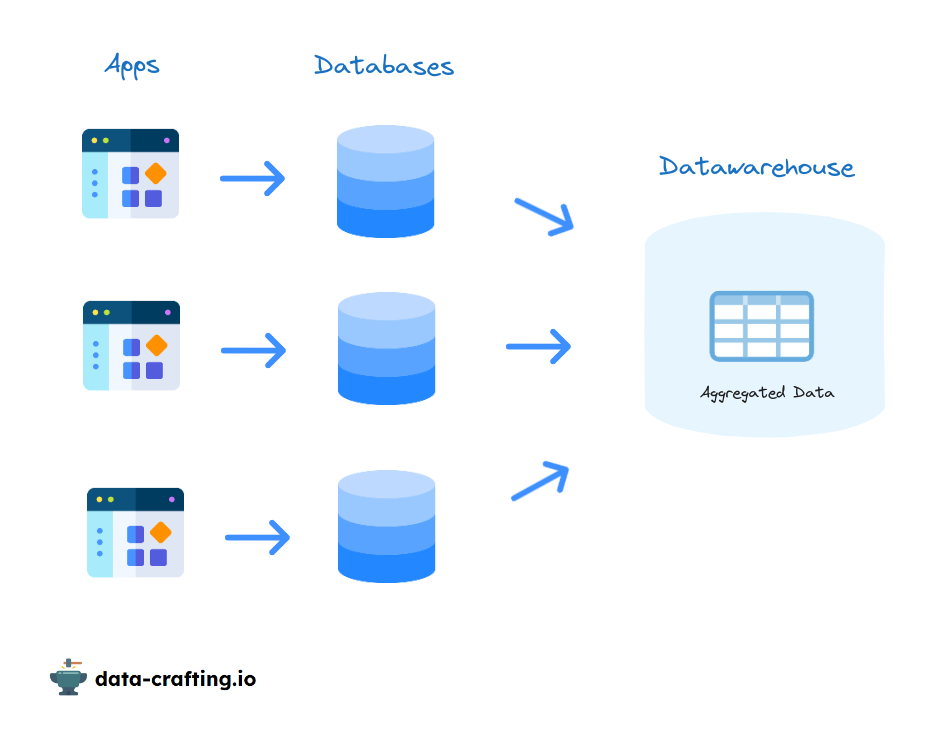
Or cette méthode est depuis assez désuète car elle implique plusieurs inconvénients :
La quantité de données à transférer peut être importante.
Nous pouvons ne pas voir certaines transactions.
Concernant les transactions, une requête sur une base de données représente l’état de vos tables qu’à un instant T. Or, il est souvent plus intéressant d’avoir l’historique des transactions effectuées.
Un exemple pour mieux comprendre :
Imaginez un site e-commerce permettant de sauvegarder votre panier de commandes.
Un client arrive sur le site, met plusieurs produits dans son panier, attend une heure ou deux, puis supprime son panier. Si vous requêtez votre BDD, vous ne verrez rien. Alors qu’en fait, il s’est passé plusieurs transactions.
Et ces transactions n’apparaîtront pas dans la donnée que vous récupérez par la suite. Alors qu’elles peuvent vous révéler de nombreuses choses, par exemple ici le nombre de clients qui ne vont pas au bout du processus d’achat.
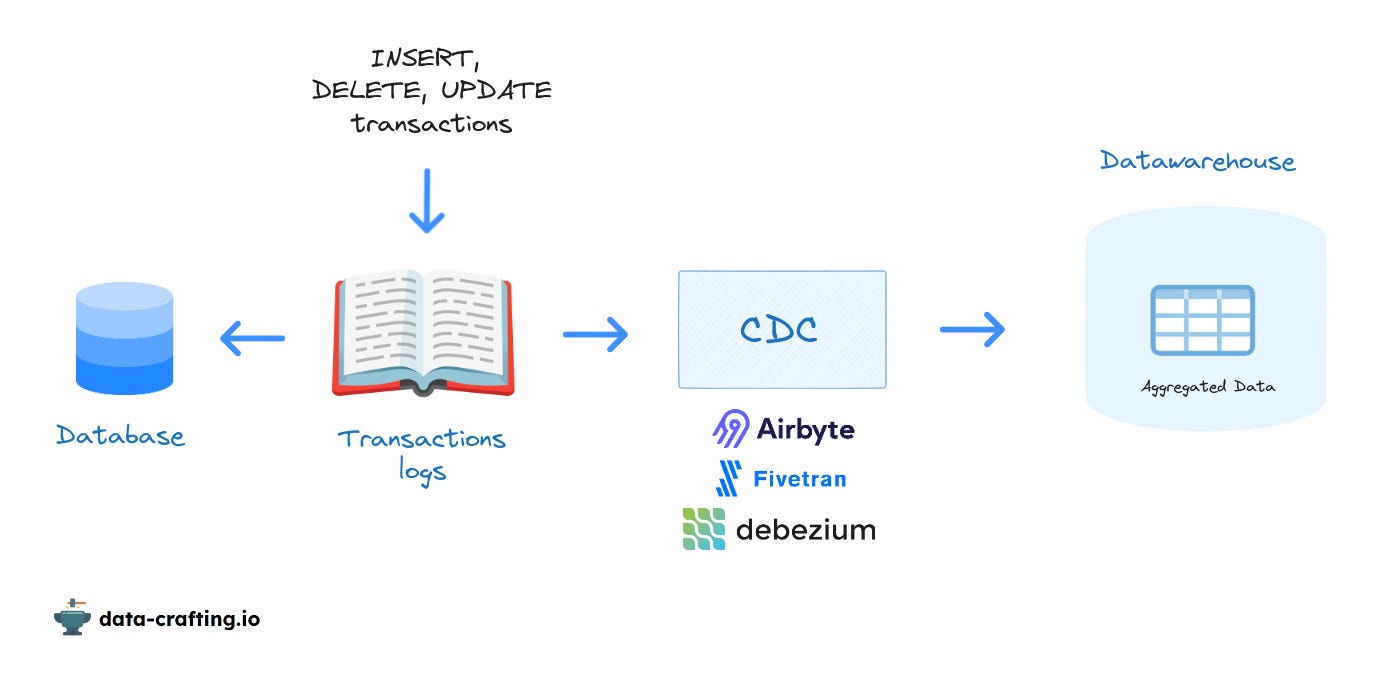
L’idéal serait donc d’ingérer au fil de l’eau chaque transaction effectuée sur nos bases de données. Ça tombe bien, il y a un moyen de faire ça, et ce moyen s’appelle le journal de transaction.
Il se trouve que les bases de données relationnelles utilisent toutes des journaux de transactions pour l'intégrité des données et permettre la récupération en cas de panne.
En effet, toutes les transactions avant d’être appliquées à la base de données sont déjà écrites dans le journal de transaction. Ce qui fait du journal de transaction la première source de vérité, ce qui permet en cas de problème de recréer la base de données dans son intégralité simplement en relisant tout le journal.
Ce type de journal est communément appelé WAL en anglais pour write-ahead log.
Pour notre cas, il suffit donc simplement de lire le journal à chaque nouvelle transaction.
Et justement, une méthode d’intégration de données fait exactement cela :
Le Change Data Capture (CDC) permet de suivre et d'enregistrer les modifications apportées aux données dans une base de données via le journal de transaction.
Le CDC sert à répliquer les données d’une base de données à une autre (c’est comme ça que fonctionnent les réplicas), mais aussi vers un DataLake ou un Datawarehouse. Ce qui permet d’avoir les données les plus récentes à disposition.
Le CDC permet aussi de faire de l’intégration en temps réel ! Et ça c’est génial lorsqu’on veut faire du traitement de données en streaming. Avec le CDC, nous allons pouvoir créer un flux d’événements (qui sont en fait nos transactions) depuis la base de données et incorporer ce flux à notre système de traitement.
Enfin, le CDC est aussi largement utilisé pour synchroniser des systèmes entre eux, notamment des microservices. Mais on sort un peu du cadre de cette newsletter.
Concernant les technologies permettant de faire du CDC, on retrouve les outils d’intégration classiques comme Fivetran ou Airbyte.
Si vous faites du Data Streaming avec Kafka, alors il y a un outil de CDC intégrable dans l’écosystème Kafka largement éprouvé : Debezium
Debezium est un outil privilégié comparé à d’autres outils comme Airbyte et Fivetran car :
-C’est un outil Open-source et très customisable
-Excellent pour le temps réel et du CDC à faible latence
-S’intègre nativement avec Apache Kafka
-Idéal pour du Big Data et des environnements complexes
Donc, si vous voulez faire du Big Data et du Streaming et que vous utilisez Kafka, Debezium est l’outil qu’il vous faut.
Il existe des connecteurs Kafka Connect Debezium (pour rappel, Kafka Connect est un outil pour intégrer des données depuis diverses sources dans Kafka ou pour l’exporter dans différents systèmes).
Tout cela est utilisable dans un cluster Kubernetes. Il est possible de faire tourner Kafka, Kafka Connect et donc aussi Debezium dans Kubernetes grâce à Strimzi.
Strimzi est justement une plateforme open source qui permet de déployer et gérer des clusters Apache Kafka sur Kubernetes.
Je travaille actuellement dans un environnement Big Data et Streaming, et nous utilisons les connecteurs Debezium Kafka Connect pour faire du CDC depuis plusieurs bases de données.
Je vous souhaite une bonne lecture de vos journaux de transactions ;).
PS: N’hésitez pas à vous adonnez à la newsletter pour recevoir d’autres contenus de ce type